Last week was without a doubt, a catastrophe for us. Monday started with multiple outages, mostly on external sources such as Office 365 Sign-Ins and phone carriers like Vocus, Telstra and others suffering network issues. These were outages we could do nothing about as we do not run those services. However, later that afternoon, our own phone service suffered an outage.
All customers affected by the 2 hours of downtime will be receiving a months credit for the VoIP PBX system.
Rest assured, we do get spammed with outage alerts the second anything happens with our VoIP cluster and we are working on having a service status page available to you.
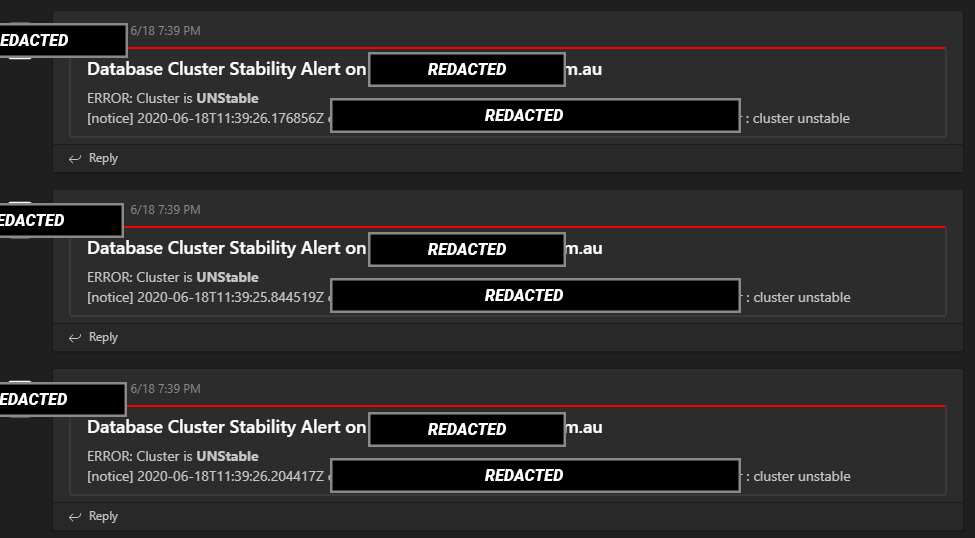
The phone outage, what goes wrong when servers can’t talk
There were two outages in the week, the first on Monday, the following on Thursday. Both were related to the database that runs the cluster of servers. When something is written to one server, it writes to all other servers at the same time. This ensures that there is redundancy, so should one database fail, there are other databases to serve the request.
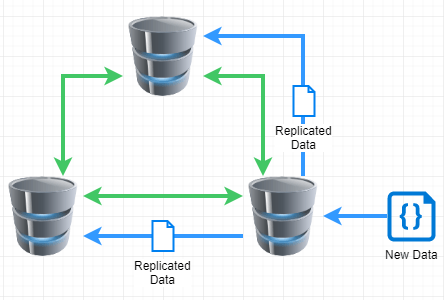
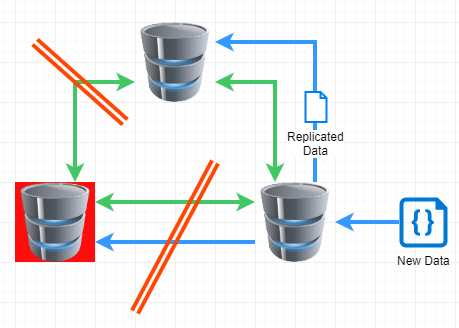
In the above example with a server down, the cluster still operates as the other two servers can agree on the new data. During our outage, none of the individual servers were down, they just couldn’t talk to each other.
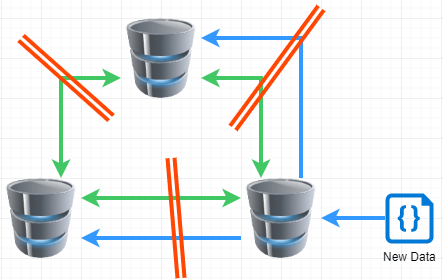
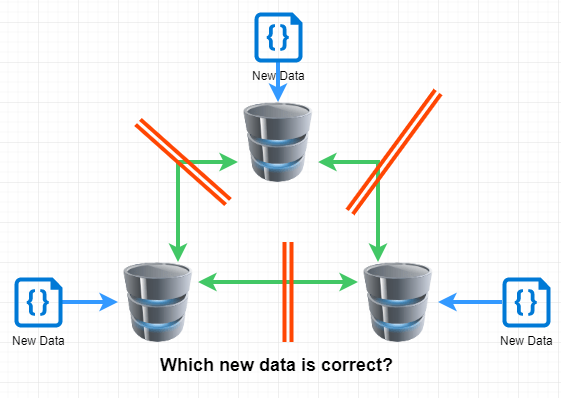
In this scenario, where the individual servers can’t talk to each other, the cluster becomes unstable. In order for it to trust new data, it must create what is called a Quorum, or a majority vote to say “this is correct”. If servers can not talk to each other, then nobody can reach a majority vote and therefore, requests to and from the database fail.
Failure in advertising, and its effect on network design
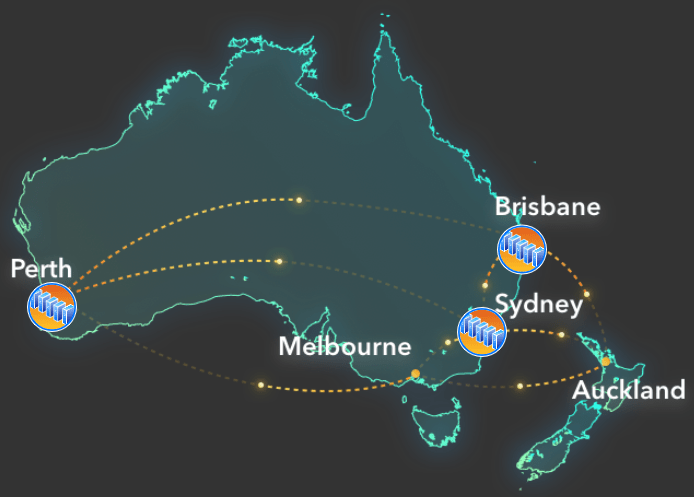
In theory, there would have to be something very wrong in multiple places to cause all servers to fail to talk to each other. Our design was based on the advertising of our datacentre provider. We place these servers in different states inside Australia and should be connected like below. This means a dedicated link from Perth to Brisbane, a dedicated link from Brisbane to Sydney and a dedicated link from Sydney to Perth.
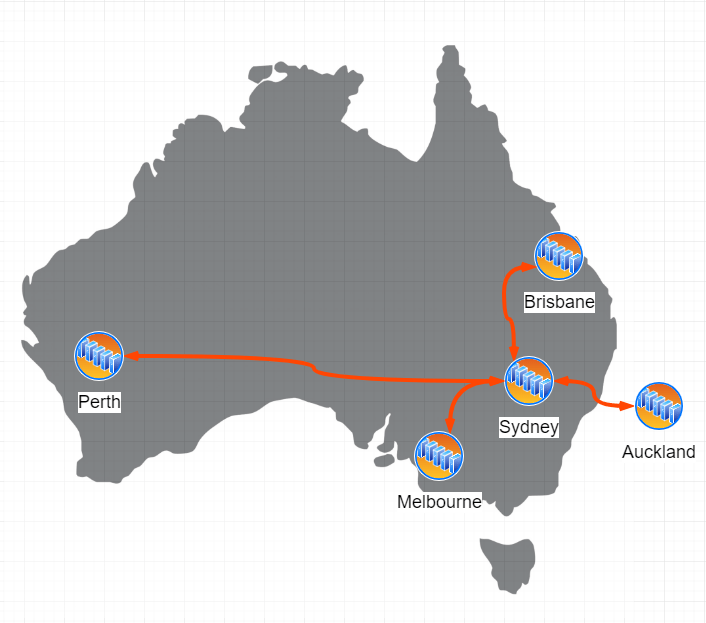
When we suffered the outage, we were advised the problem was with a core router inside Sydney. But we saw that traffic between Perth and Brisbane was interrupted, so what was up? We investigated and found, despite the advertising, this is what their network map really looks like. With everything connected via Sydney. This meant a single point of failure.
Lessons Learned
We provisioned a new separate link for us between Perth and Brisbane. However, this was going to take a few days and we suffered another outage in Sydney on Thursday before this new link could be installed. Today, that link is operational and our cluster should no longer be brought down by a single router in Sydney.
We really understand to not trust any marketing information and instead, verify.
We also noted that when we suffered the outage, calling each customer to get a divert in place was very inefficient. In fact, by the time we managed to contact half our customers, the issues had been resolved. We will be working with our customers to have a divert number on file/record so should we have an outage again, we can automate the switch to the failover number.